Programmable Sparse Attention for Agents as Algorithm Designers
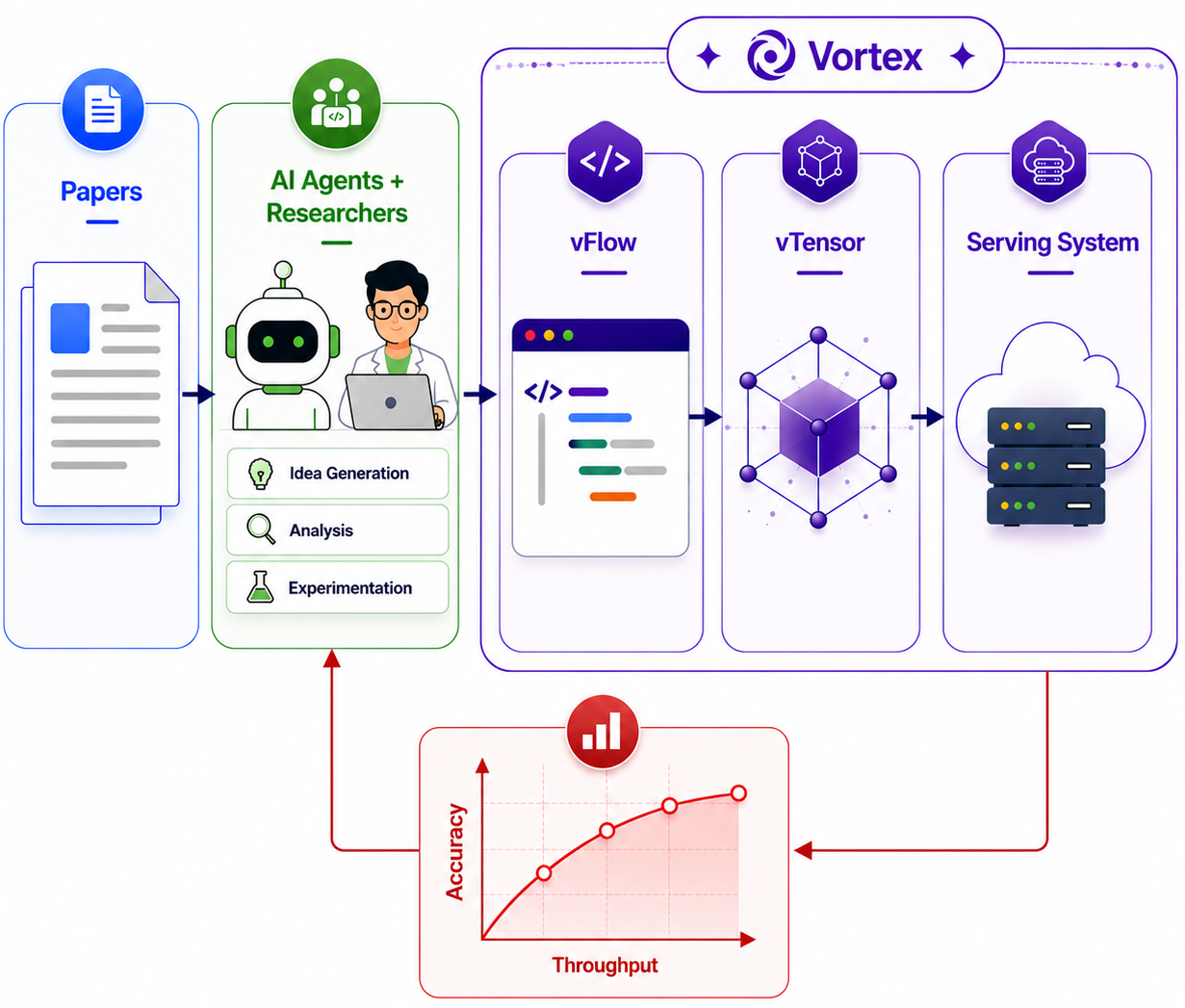
Vortex turns sparse-attention algorithm design into something AI agents can do — express a flow in a few lines of Python, and Vortex deploys and benchmarks it inside a real LLM serving stack in minutes.
throughput of agent-generated sparse attention vs. full attention, accuracy preserved
4.7×
throughput on the MLA-based GLM-4.7-Flash
1.37×
throughput on the 229B-parameter MiniMax-M2.7
★ Highlights
Agents discover sparse attention — and it actually runs faster
AI agents generate and refine diverse sparse-attention algorithms with Vortex, and every one is benchmarked end-to-end in a real serving stack — so these are measured throughput gains, not paper estimates. The headline results:
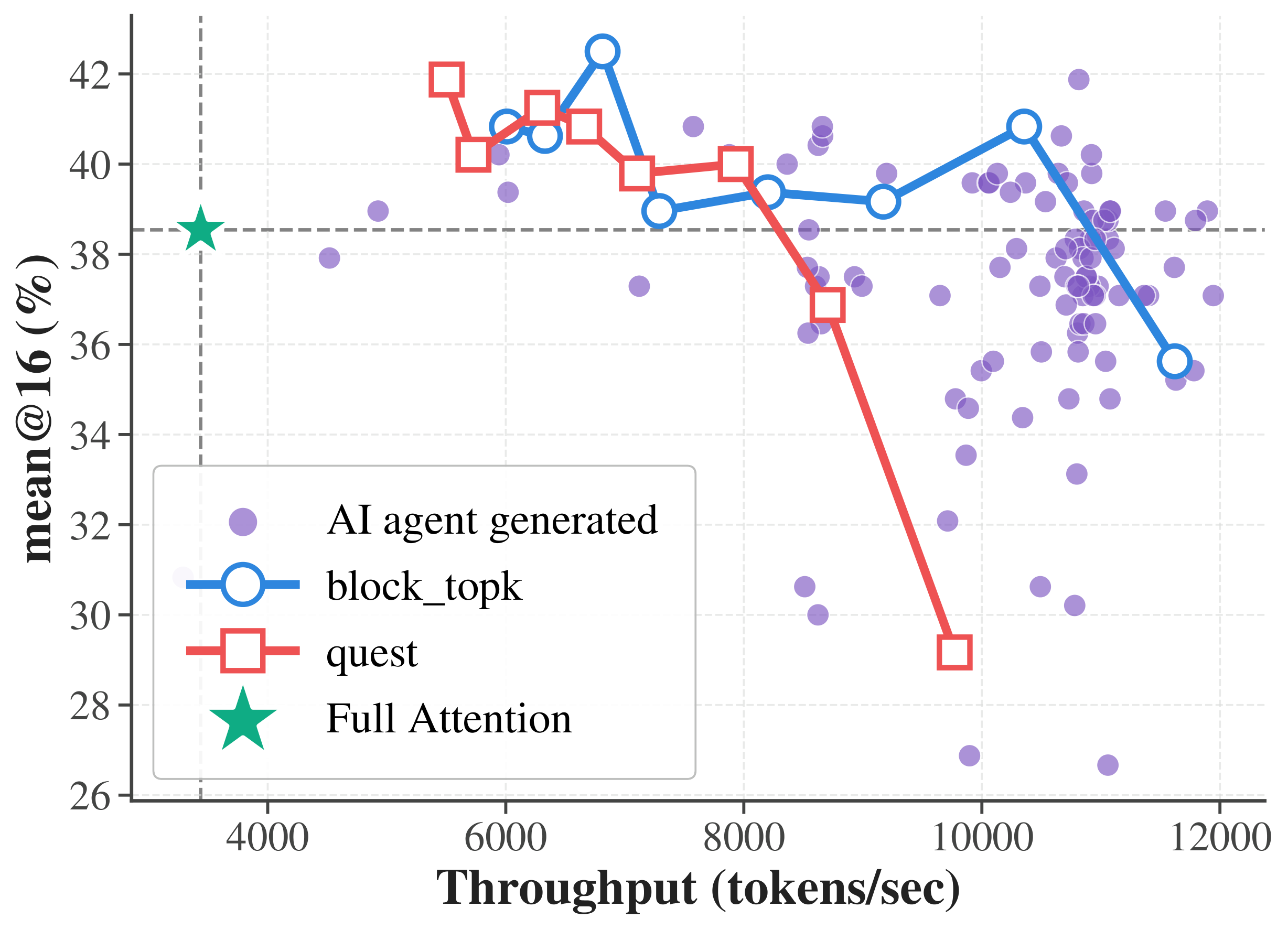
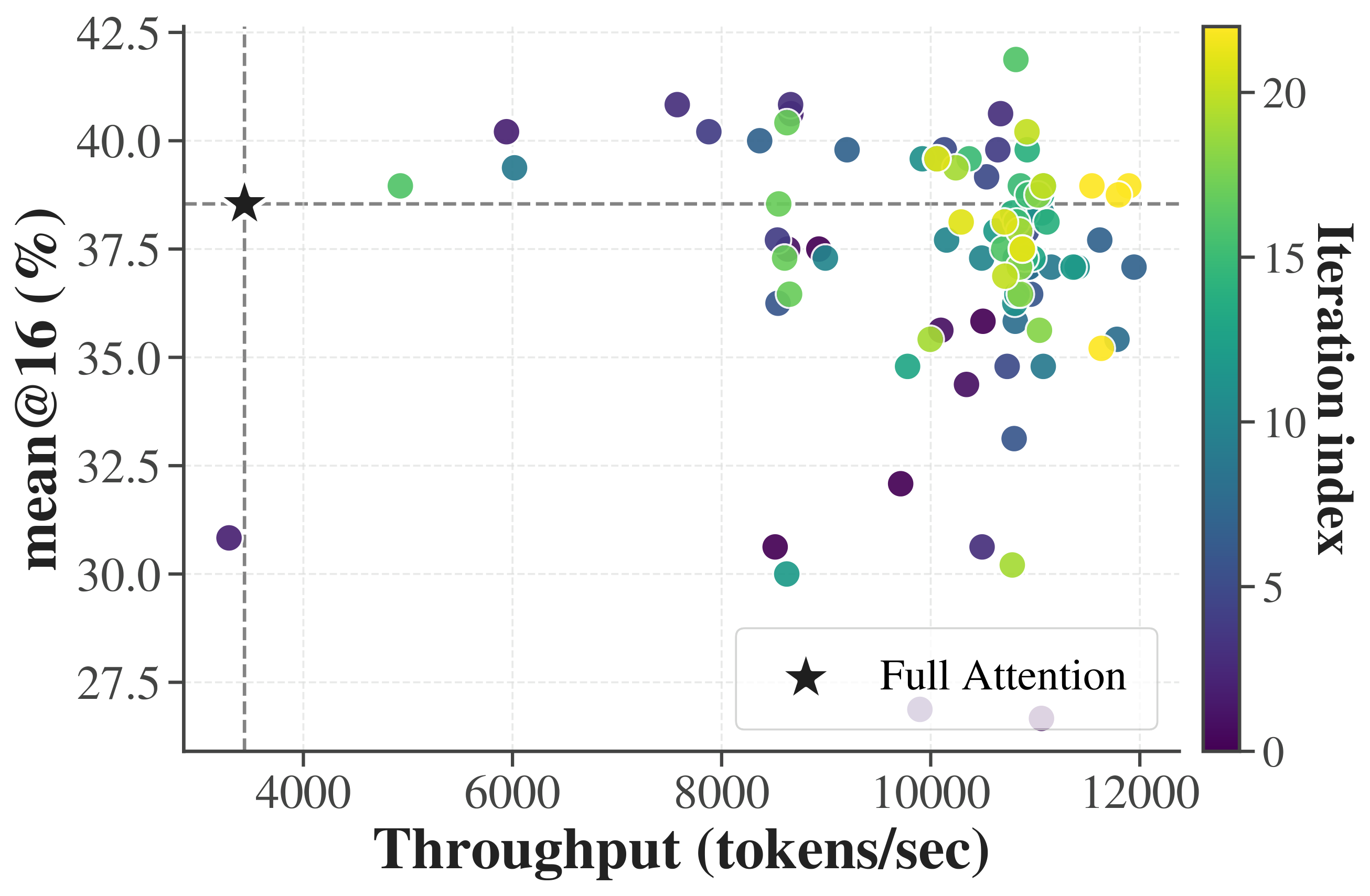
From idea to deployed algorithm. A researcher or agent writes a flow over Vortex's page-centric tensor abstraction, and it compiles into fused kernels that plug straight into SGLang. The payoff is immediate: across agent-generated variants, the best reaches up to 3.46× the throughput of full attention while preserving accuracy.
(a) A workflow to study sparse attention with Vortex. (b) Agent-generated sparse attention (Qwen3-1.7B, AIME, NVIDIA H200) — the best reaches up to 3.46× the throughput of full attention while preserving accuracy.
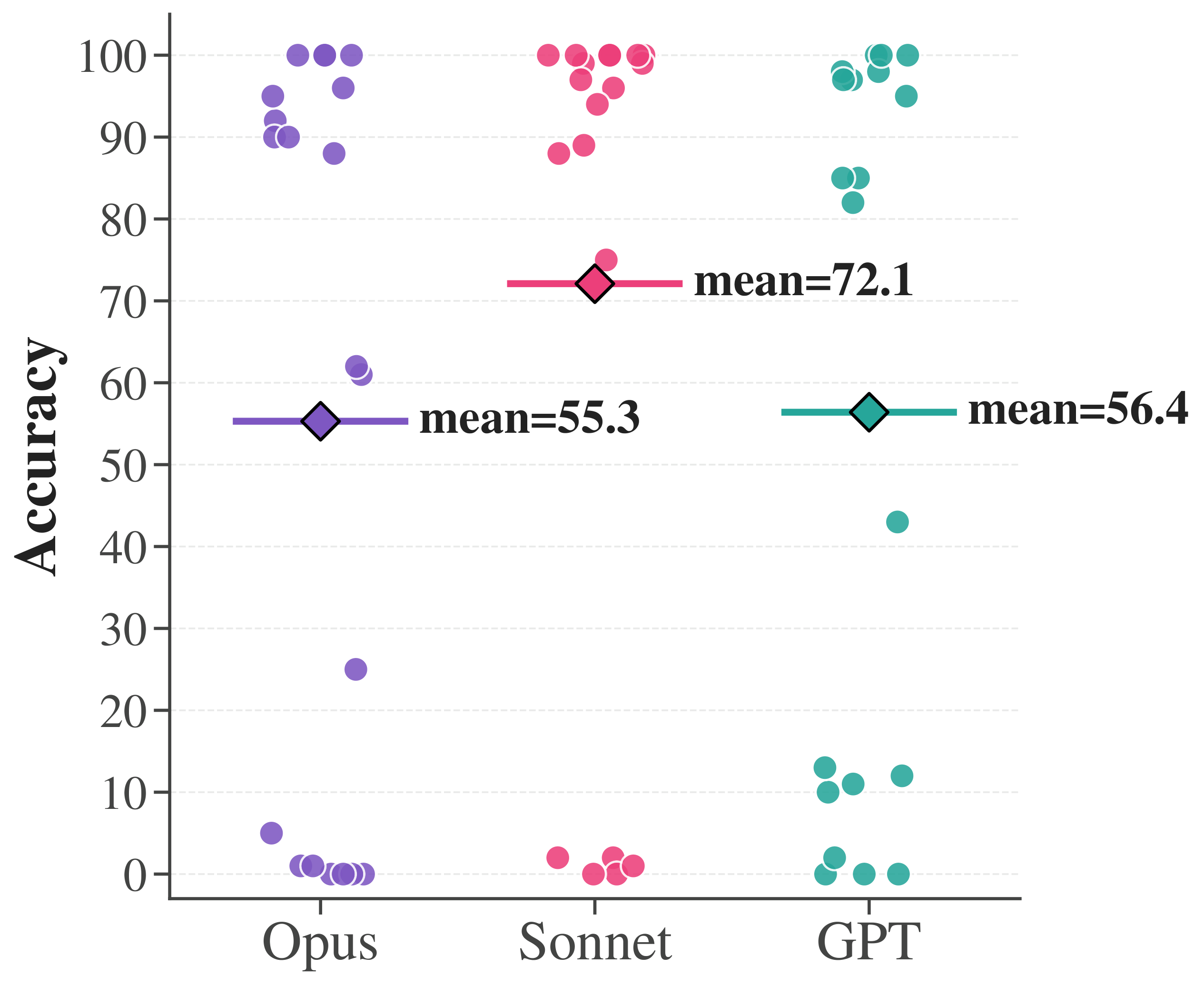
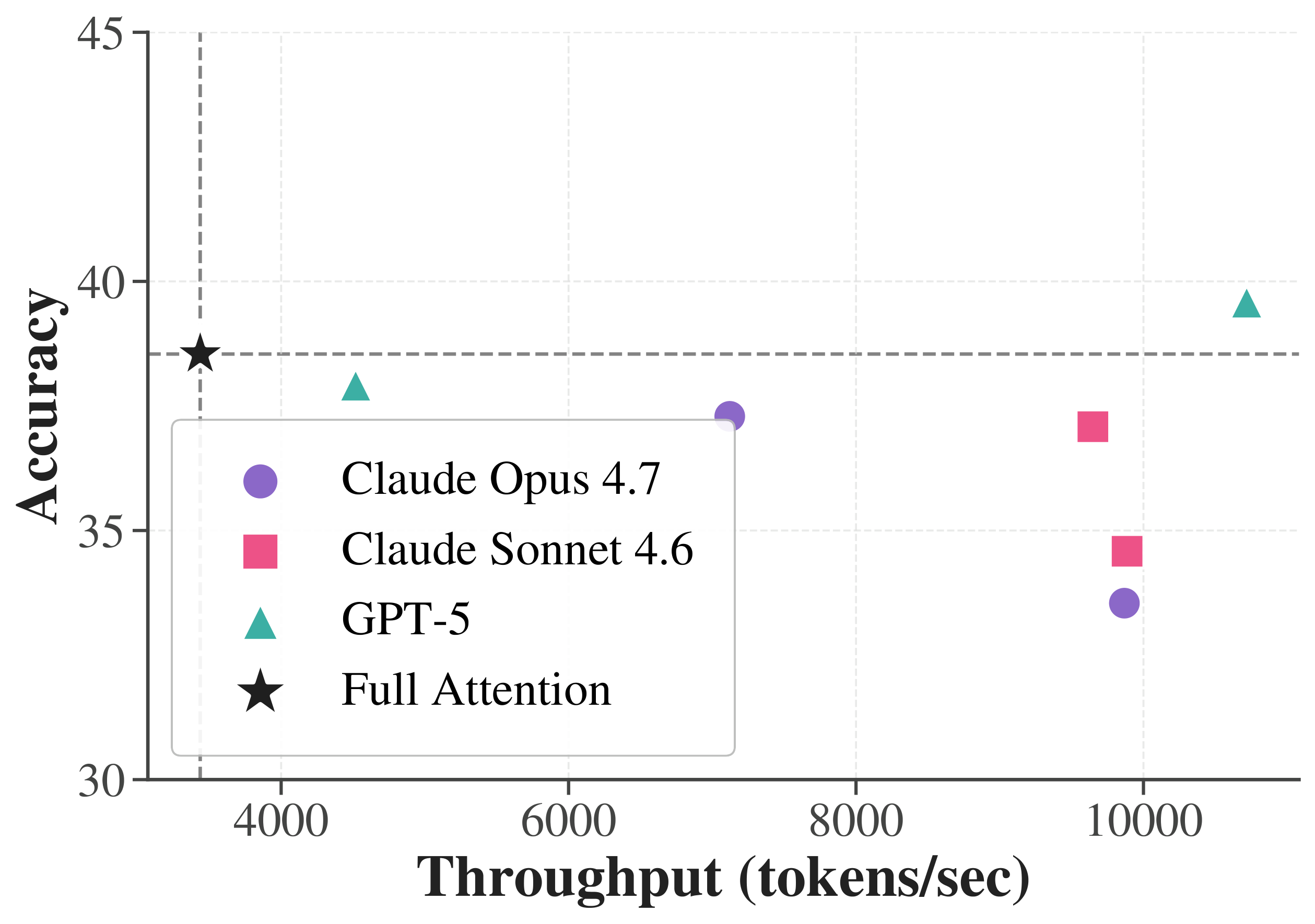
Many agents, many algorithms. This isn't one hand-tuned kernel. Claude Opus 4.7, Claude Sonnet 4.6, and GPT-5 each generate structurally diverse designs — and after a staged filtering pipeline, the selected ones are efficient: full-attention accuracy at 2–3.1× higher throughput across three benchmarks.
Performance of AI-agent-generated algorithms across (a) RULER, (b) AMC23, and (c) AIME24 — Claude Opus 4.7, Claude Sonnet 4.6, and GPT-5 each produce diverse sparse-attention designs; after a staged filtering pipeline, the selected ones are efficient — full-attention accuracy at substantially higher throughput.
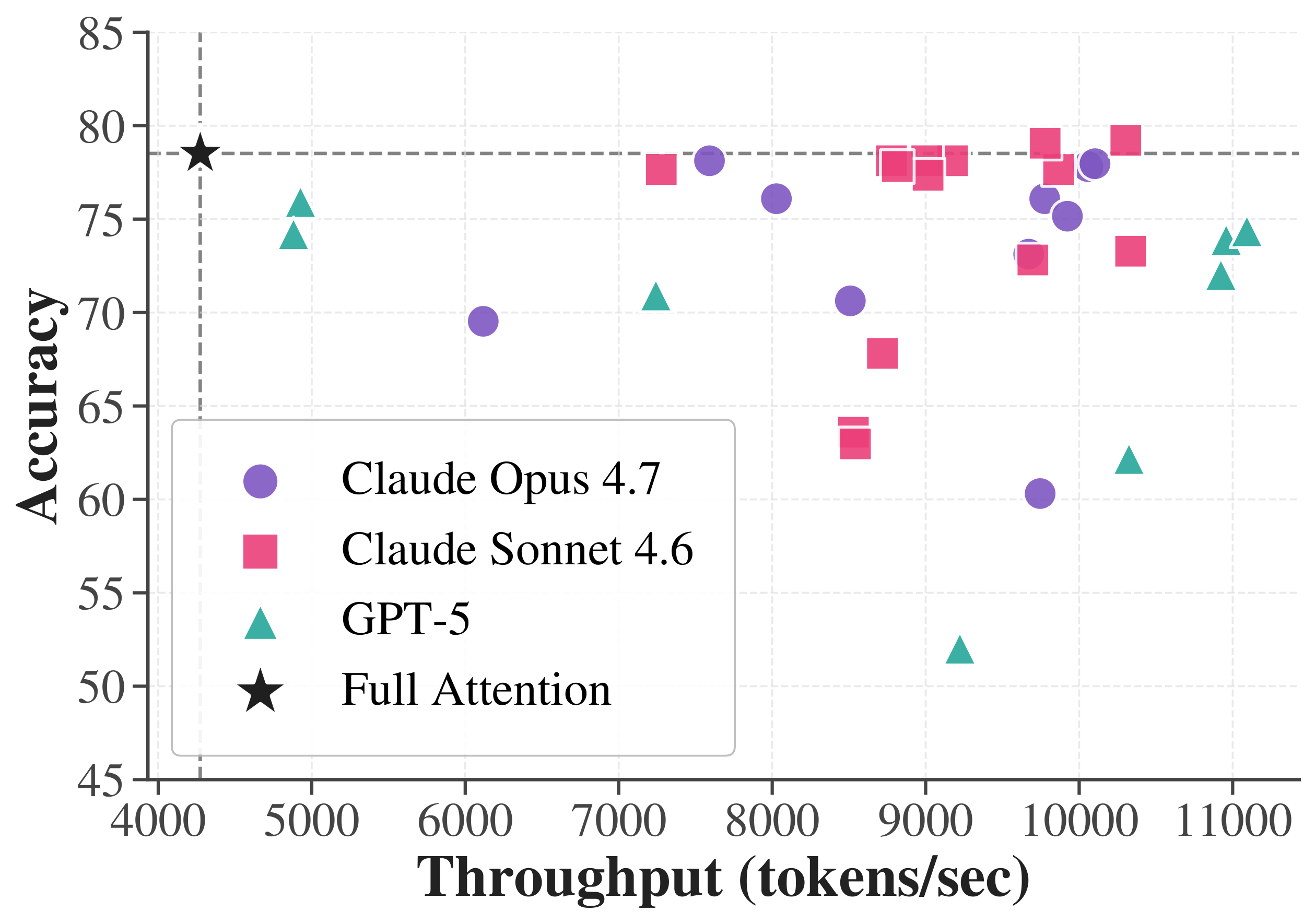
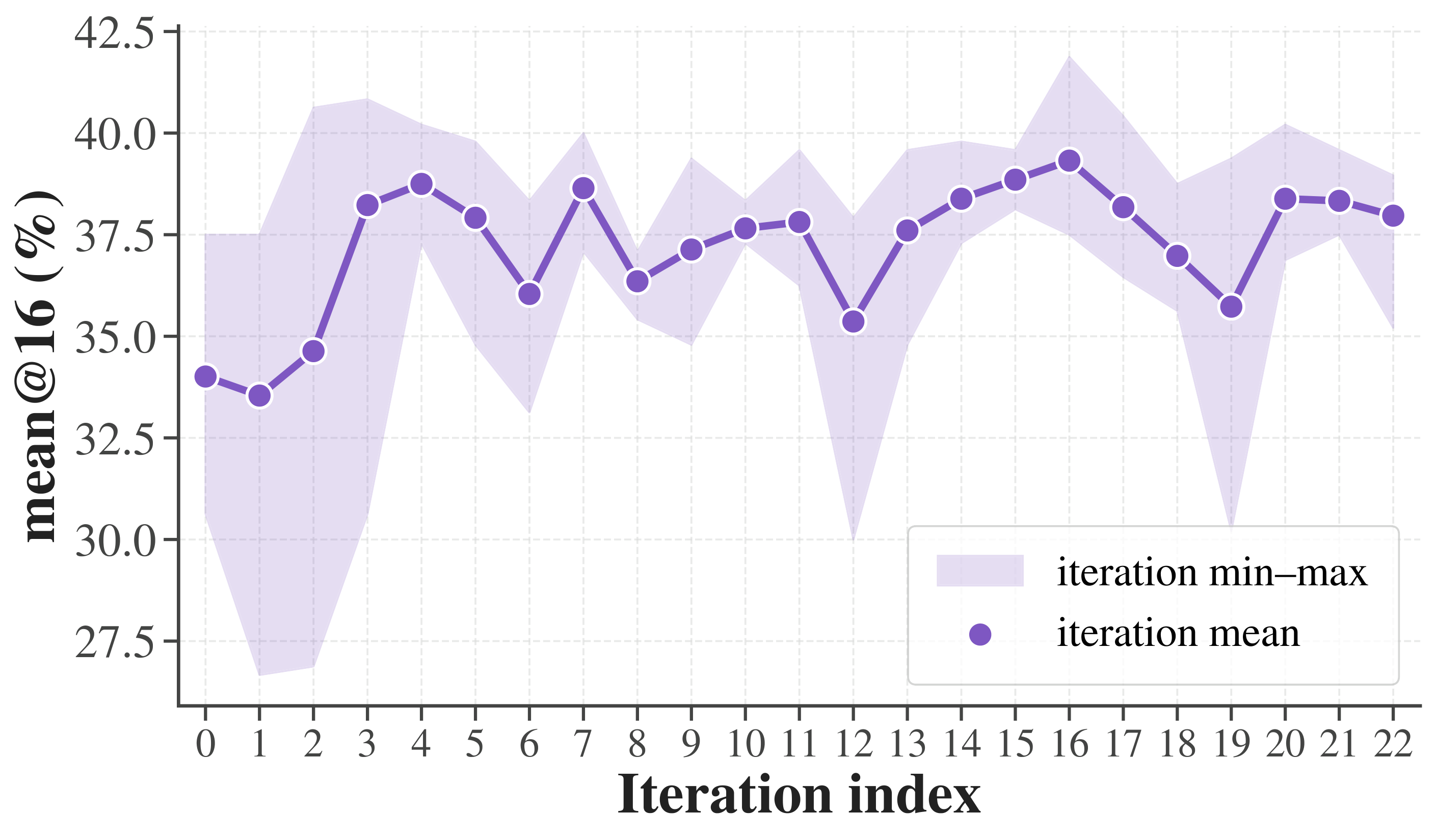
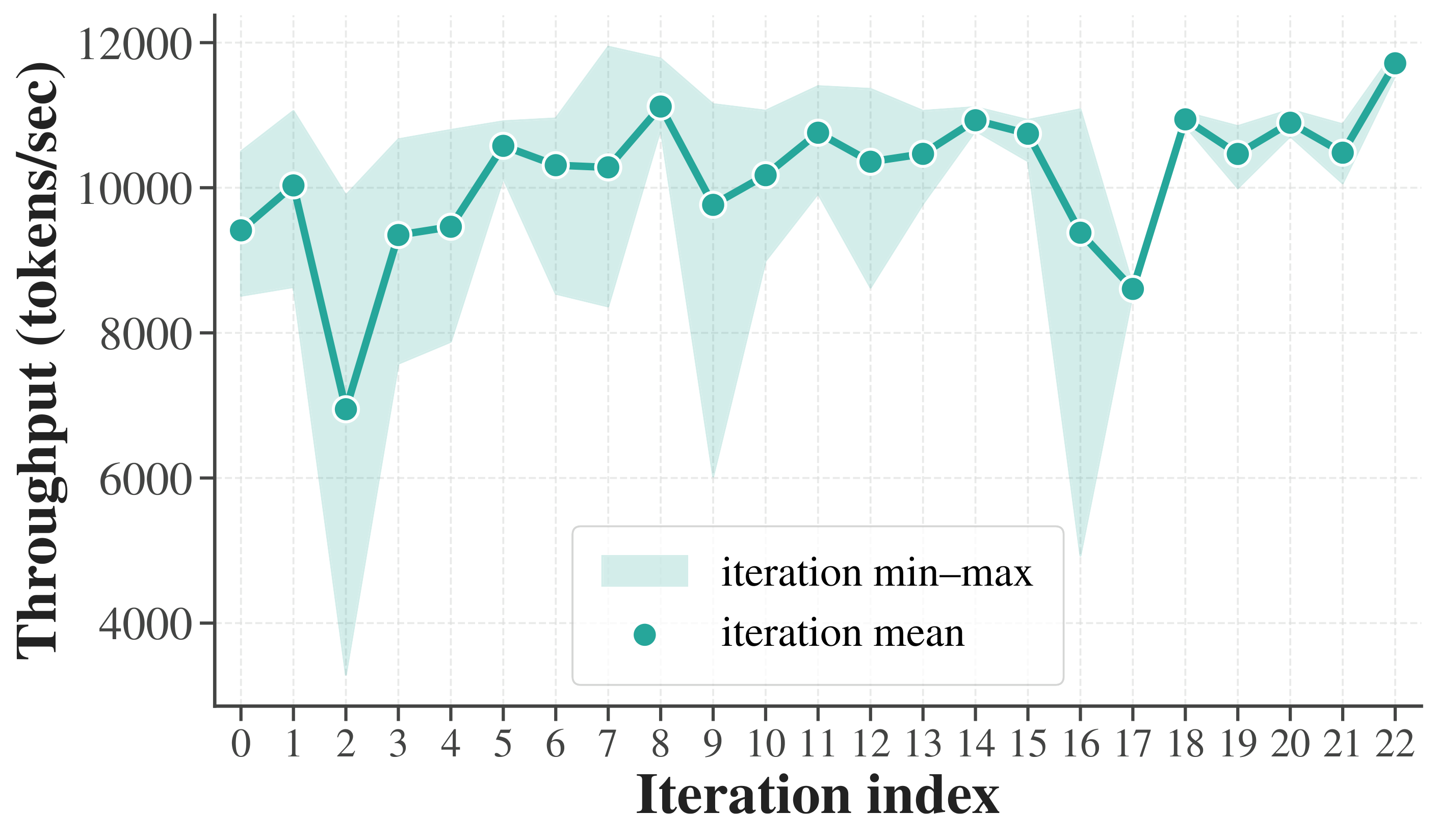
And it compounds. Given only the framework and a goal, an agent runs a long-horizon loop — proposing, benchmarking, and refining four variants per round. Over 18 hours (23 iterations, 92 submissions) it steadily pushes the accuracy–throughput frontier outward, entirely on its own.
Long-horizon autonomous optimization on AIME24 (23 iterations, 92 submissions): (a) mean@16 per iteration, (b) throughput per iteration, (c) the accuracy–throughput frontier of all submissions, colored by iteration order.
01 · Vision
Agents as algorithm designers
Sparse attention has become a fundamental technique for serving large language models. As generation lengths explode across reasoning, agentic systems, and reinforcement learning, moving the KV cache during decoding — not compute — is the dominant bottleneck. Attending to only the tokens that matter is the way out, and it now appears both as a core architectural choice in frontier models (DeepSeek, GLM) and as a drop-in optimization for pretrained ones.
Yet deploying and evaluating new sparse-attention algorithms at scale, with real end-to-end speedups, has stayed painfully engineering-intensive — slowing both human researchers and the emerging class of AI agents that could explore this design space. Modern serving systems store the KV cache in a non-contiguous, paged, block-sparse layout reached through indirect addressing, which breaks the contiguous-tensor assumptions of frameworks like PyTorch. As a result, a new idea that is a few lines of math on paper can take thousands of lines of kernel and plumbing code to try.
Vortex removes that wall. It is built for autonomous algorithm discovery: an AI agent proposes a sparse-attention idea, expresses it in a few lines of high-level Python, and Vortex compiles it into fused kernels that run inside a production serving stack — then measures real throughput and accuracy. The agent reads the result and refines, closing the research loop without a human in the inner iteration.
Across hundreds of generated variants, agents consistently discover Pareto-efficient algorithms: full-attention–level accuracy at a fraction of the cost. The best reaches up to 3.46× higher throughput than full attention while preserving accuracy — and because every variant is benchmarked in a real serving stack, those gains are measured, not theoretical.
It runs as a closed discovery loop:
1
Express
An agent writes the idea in a few lines of high-level Python ops — scoring, reductions, top-k.
→
2
Deploy
Vortex JIT-compiles it into fused kernels inside a real LLM serving stack — no model-code changes.
→
3
Measure
Real throughput and accuracy come back from an end-to-end benchmark, not an estimate.
↺
4
Refine
The agent reads the result and proposes the next variant — discovery without a human in the inner loop.
02 · Design
A frontend for ideas, a backend for serving
Vortex pairs a Python-embedded frontend over a page-centric tensor abstraction (vTensor) — concise enough to express a broad range of sparse-attention algorithms — with an efficient backend tightly integrated into modern LLM serving stacks (SGLang). The guiding principle is a clean split: you say what sparsity to apply and how attention is computed, and the framework owns the low-level tensor layout and memory management. Theoretical efficiency becomes real-world throughput, without touching core model code.
You describe what to attend to — score pages, reduce per-block summaries, select a top-k — and Vortex handles batching, paged KV caching, gather minimization, and kernel fusion. A flow is written as modular, composable operators (GeMM, Reduce, Top-K, …) over paged tensors, rather than a monolithic custom kernel per algorithm — so new patterns combine instead of being reimplemented from scratch.
Crucially, Vortex treats the dynamic part — deciding the sparsity pattern on the fly — as a first-class, optimized stage, not an afterthought. The same abstraction covers MHA and MLA models, exact and approximate top-k, and even a programmable per-sequence token budget written as a small CUDA snippet.
The result drops into FlashInfer / CUDA Graph / radix-cache decoding — so a new algorithm is deployable and benchmarkable the moment it compiles, and its speedups survive contact with a real serving system.
Under the hood, a flow flows through three composable layers:
▣
vFlow
A Python-embedded frontend language. Declare what to attend to; the framework handles batching, caching, and fusion.
▦
vTensor
A page-centric tensor abstraction where the page is the unit of sparsity — uniform across MHA and MLA models.
▤
Serving System
A backend tightly integrated with SGLang: FlashInfer kernels, CUDA Graph, and radix-cache decoding.
Together, these close three gaps that have kept sparse attention slow to iterate on:
⚙︎
Dynamic sparsity
Static-pattern kernels (FlashInfer, FlexAttention) optimize attention once the pattern is known. Vortex makes computing the pattern on the fly — the accurate, dynamic case — efficient too.
⌘
Programmability
Adding a variant to a serving system can mean ~2000 lines of code re-implementing GeMM/Reduce/Top-K over paged tensors. In Vortex it is a few composable lines.
🔌
Serving compatibility
Custom-kernel methods often break paged attention or prefix caching — Quest's original code is 44.4× slower than full attention. Vortex stays native to the stack.
03 · Experiments
Discovery, scale, and emerging architectures
Vortex accelerates sparse-attention research along three axes: autonomous discovery, reach into emerging architectures and very large models, and use as a research instrument for understanding where the routing signal lives.
①
Autonomous discovery
Agents generate and refine diverse algorithms that are consistently Pareto-efficient.
up to 3.46× throughput
②
Scale & architectures
Sparse attention extended to MLA models and very large models that are otherwise hard to experiment with.
4.7× GLM-4.7 · 1.37× 229B
③
Research instrument
A lens on sparse attention itself — pinpointing where the routing signal lives.
interpretability
Autonomous discovery is shown in the Highlights above; here we focus on reach — new architectures and the largest models:
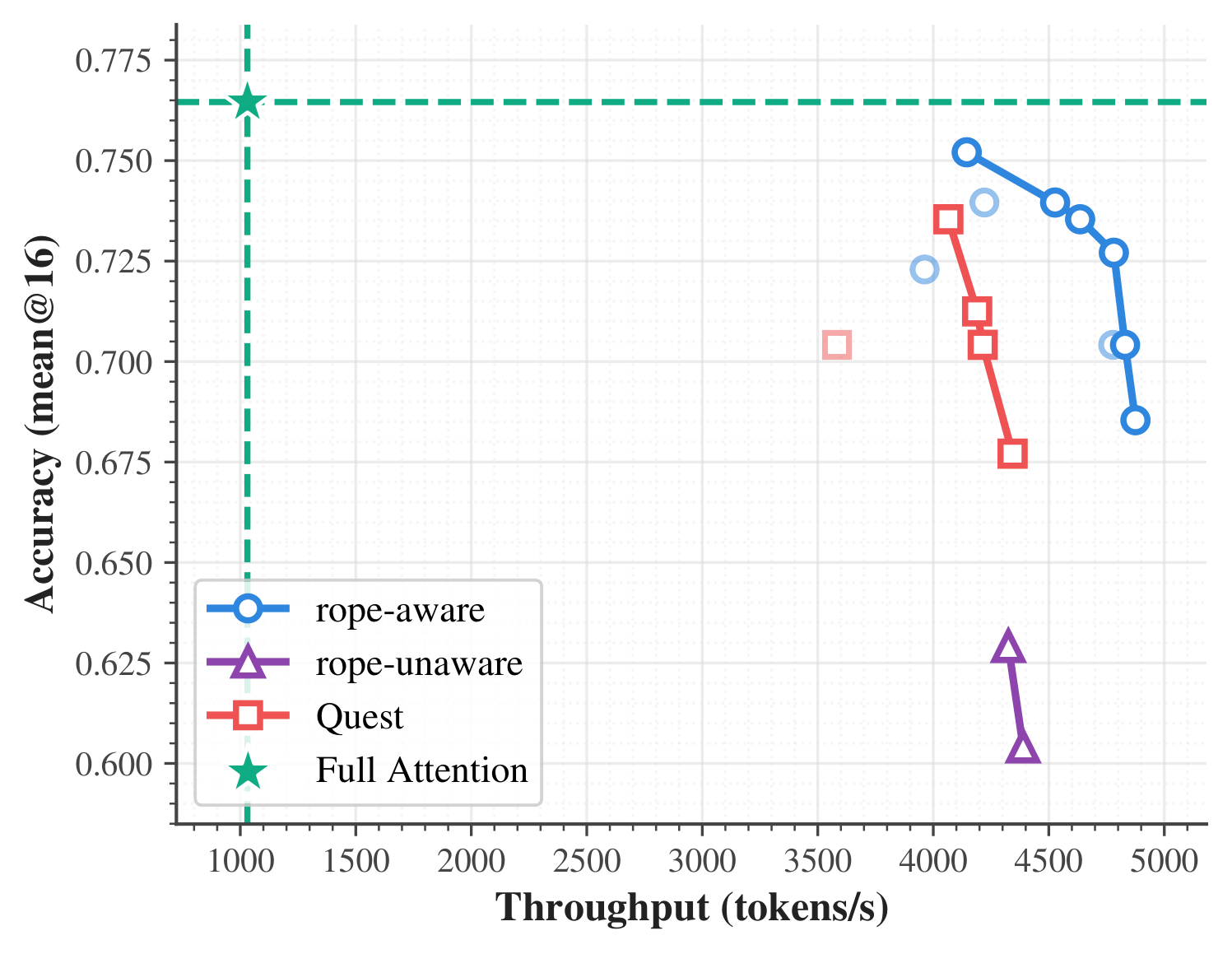
MLA models
GLM-4.7-Flash · up to 4.7×
Three MLA sparse-attention flows (rope-aware / rope-unaware block-sparse, and Quest) expressed in vFlow and swept over block sizes on AIME26 with 32K-token generation — extending sparse attention to an architecture that is otherwise hard to experiment with (NVIDIA B200).
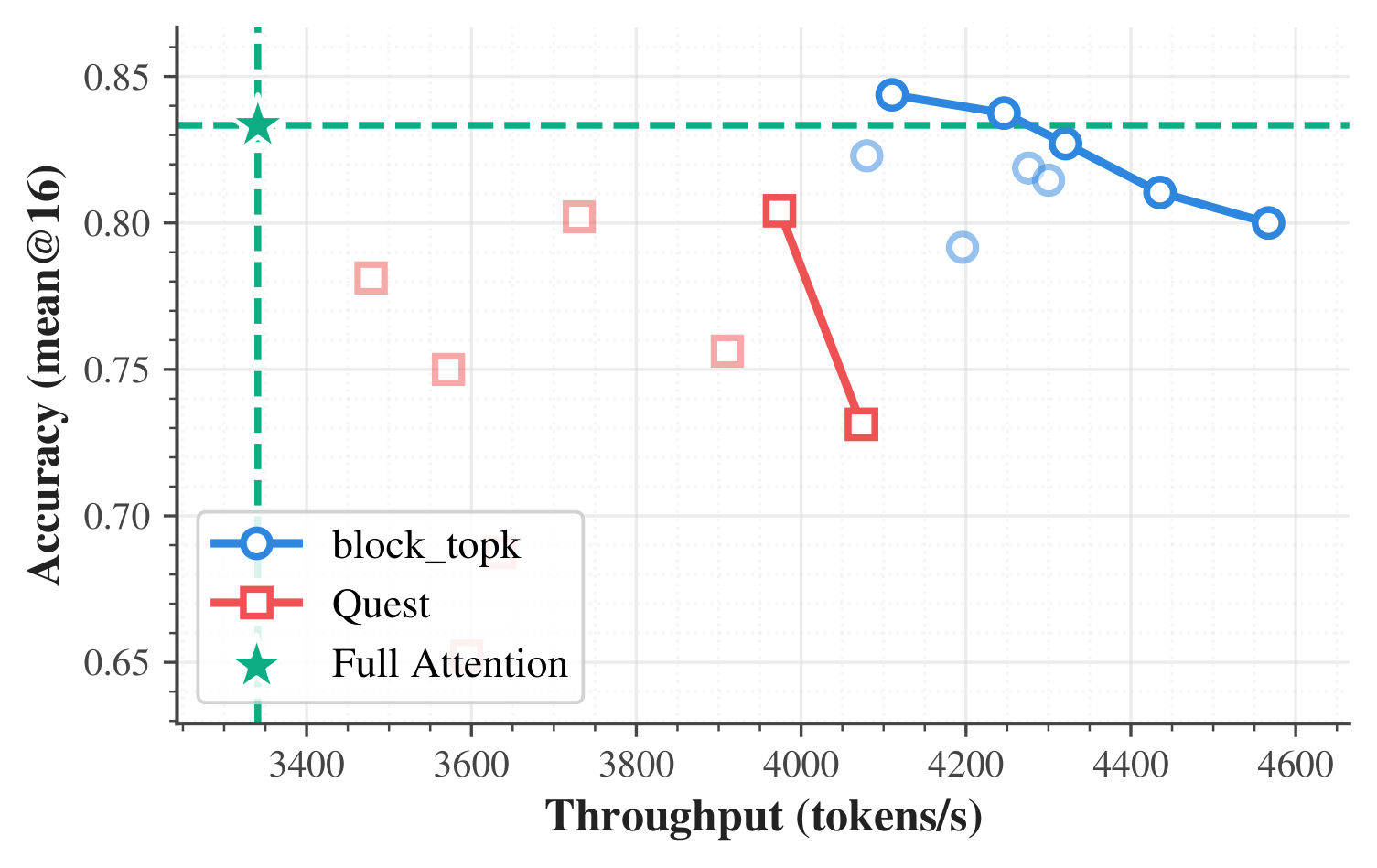
Scaling · 229B
MiniMax-M2.7 · up to 1.37×
The same flows scale to a 229B-parameter model under tensor parallelism (TP=4, four NVIDIA B200 GPUs) on AIME26 — sparse attention staying practical at the largest scales, with full-attention accuracy preserved.
Model
Benchmark
Hardware
Throughput vs. full attn
Accuracy
Qwen3-1.7B agent-discovered
AIME24
H200
↑ 3.46×
matched (38.96 vs 38.54)
GLM-4.7-Flash MLA
AIME26 · 32K
B200
↑ 4.7×
matched (mean@16 ≈ 0.75)
Qwen3-30B-A3B MoE, FP8
AIME24 · 32K
B200
↑ 1.63×
matched (0.802 vs 0.80)
MiniMax-M2.7 229B, TP=4
AIME26 · 32K
4× B200
↑ 1.37×
≥ full (0.84 vs 0.83)
Best operating point per model; “throughput vs. full attn” is end-to-end decode throughput at matched-or-better accuracy. Block top-k also reaches up to 3.60× server throughput and 11.7–12.8× lower P95 latency at high request rates.
Because every algorithm is benchmarked end-to-end in a real serving stack, these are measured throughput gains, not paper estimates. Beyond raw numbers, Vortex doubles as a research instrument: agents produce structurally diverse algorithms, and controlled ablations using the same abstraction localize where the routing signal lives — a small set of query–key channel groups turns out to carry most of the routing information across model sizes.
Get started
Install in a minute
Install
git clone --recursive https://github.com/Infini-AI-Lab/vortex_torch.git
cd vortex_torch
# SGLang dependency (vendored)
cd third_party/sglang/v0.5.9/sglang
pip install -e "python"
cd ../../../../
# Vortex
pip install -e .
Cite
@misc{chen2026vortexefficientprogrammablesparse,
title = {Vortex: Efficient and Programmable Sparse Attention Serving for AI Agents},
author = {Zhuoming Chen and Xinrui Zhong and Qilong Feng and Ranajoy Sadhukhan and
Yang Zhou and Michael Qizhe Shieh and Zhihao Jia and Beidi Chen},
year = {2026},
eprint = {2606.06453},
archivePrefix = {arXiv},
primaryClass = {cs.AI},
url = {https://arxiv.org/abs/2606.06453}
}