Our design of TriForce is inspired by three critical empirical observations regarding LLMs when dealing with long contexts, detailed as follows.
 Leveraging Attention Sparsity for Speculative Decoding
Leveraging Attention Sparsity for Speculative Decoding
As shown in the figure below, the Llama2-7B-128K model demonstrates significant attention sparsity with a 120K context. We observe that with a context length of 120K, it is possible to recover over 96% of the attention score with merely 4K tokens across almost all layers. The presence of sparsity within the attention blocks suggests that a fraction of KV cache could serve as a draft cache to attain a high acceptance rate during self-speculative decoding.
The necessity of keeping the entire KV cache in our settings allows us to select KV cache freely. In our approach, KV cache is segmented into small chunks. During the retrieval phase, we calculate the attention between a given query and the average key cache within each chunk. This method effectively highlights the most relevant chunks, enabling us to gather KV cache with a fixed budget based on the scores. By focusing on relevance over recency, retrieval-based policy demonstrates its potential to handle contextually dense datasets.
 Exploiting Contextual Locality for Drafting Efficiency
Exploiting Contextual Locality for Drafting Efficiency
Our exploration reveals that the information from long context tokens needed by adjacent tokens tends to be similar. With the context length established at 120K, we instruct the model to generate 256 tokens. By choosing the top-4K indices according to the attention scores of the last prefilled token, we use these indices to gather attention scores for the subsequently generated tokens and assess the score's recovery rate for the initially prefilled 120K tokens. It leads to high recovery across most layers and a slowly decreasing trend as the number of tokens increases.
This observation allows for a single construction of the cache to suffice for multiple decoding steps, thereby amortizing the latency of constructing draft cache and boosting efficiency. As new KV cache are introduced, guided by the understanding that recent words are more strongly correlated with the tokens currently being decoded, these entries will replace the less significant ones. Cache re-building operations can be scheduled at regular intervals or adaptively in response to a drop in the acceptance rate, which ensures that the cache remains dynamically aligned with the evolving context.
 Hierarchical Speculation
Hierarchical Speculation
While addressing the KV cache bottleneck enhances efficiency, the requirement to load whole model weights for drafting reintroduces latency, shifting the bottleneck to model weights again. To tackle this challenge, we implement a hierarchical system. This system employs a secondary, lightweight model with StreamingLLM cache to perform initial speculations for our target model with retrieval-based draft cache (which serves as a draft model for the target model with full KV cache). By establishing this sequential speculation hierarchy, we effectively reduce the latency associated with drafting, thereby accelerating the overall inference.
 Introduction
Introduction Long Sequence Generation with TriForce
Long Sequence Generation with TriForce Summarize a Book of 127K Tokens
Summarize a Book of 127K Tokens TriForce: Hierarchical Speculative Decoding
TriForce: Hierarchical Speculative Decoding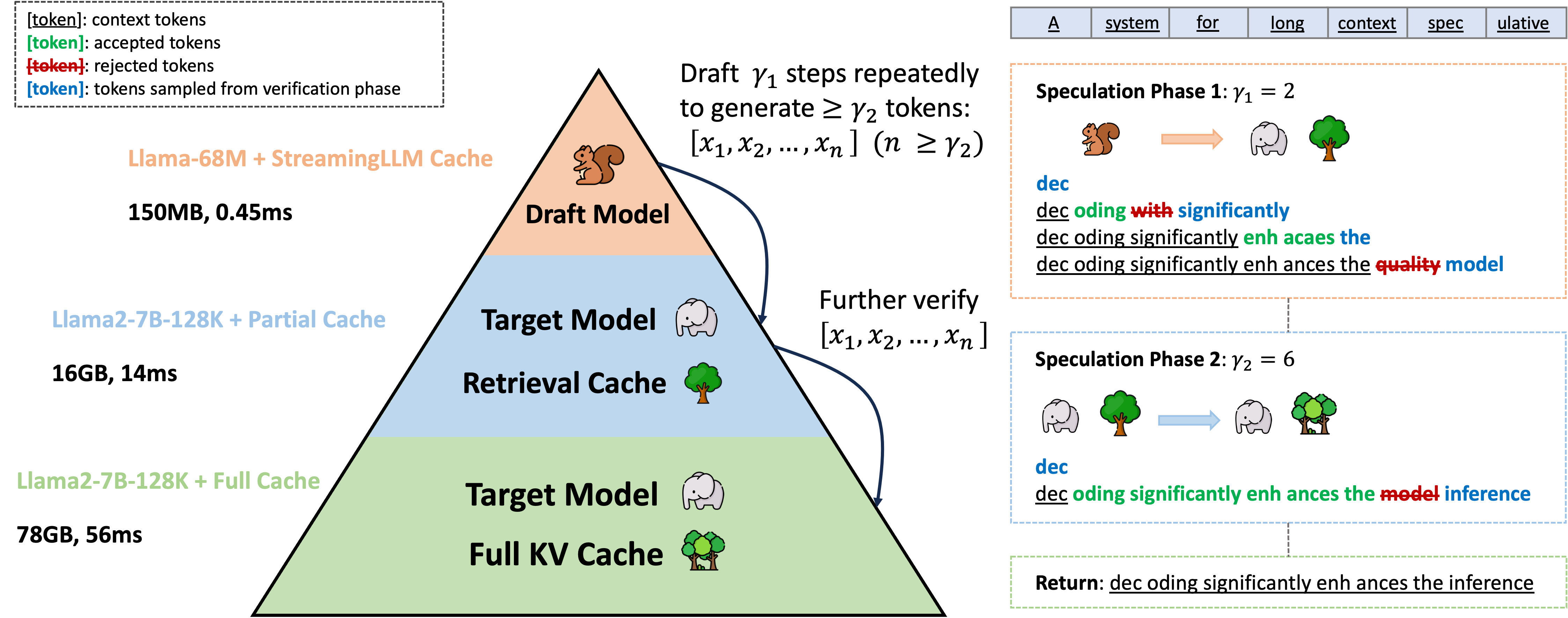
 Motivation of TriForce
Motivation of TriForce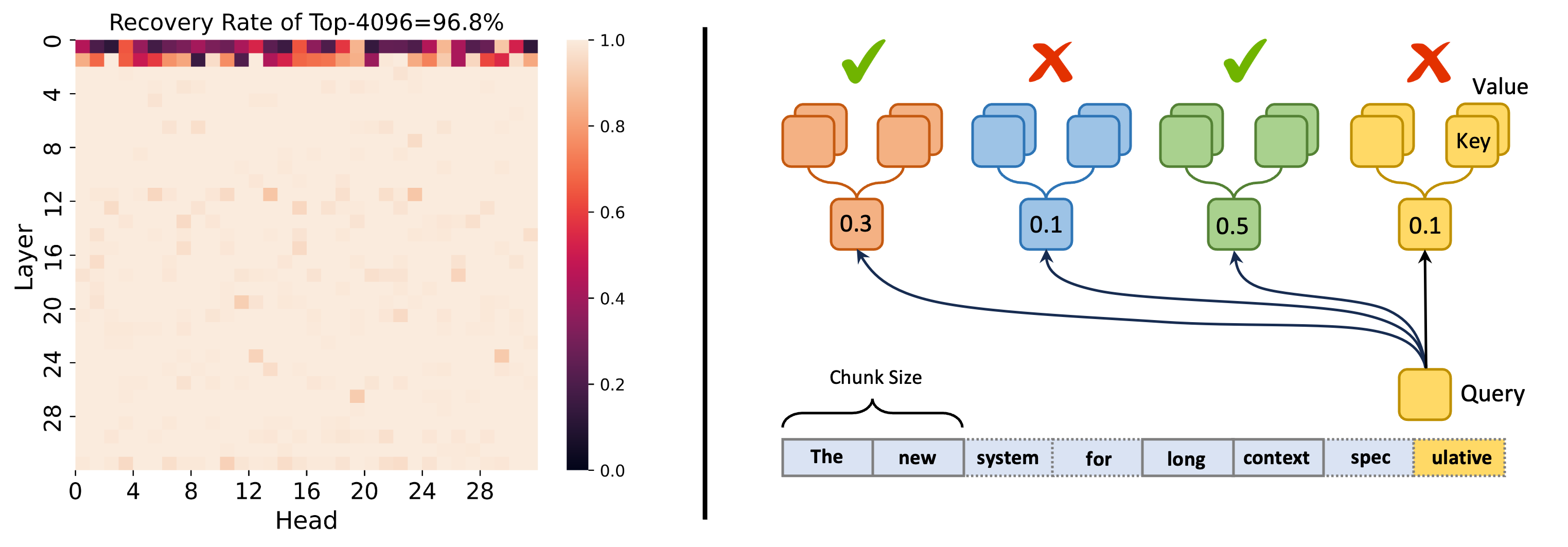
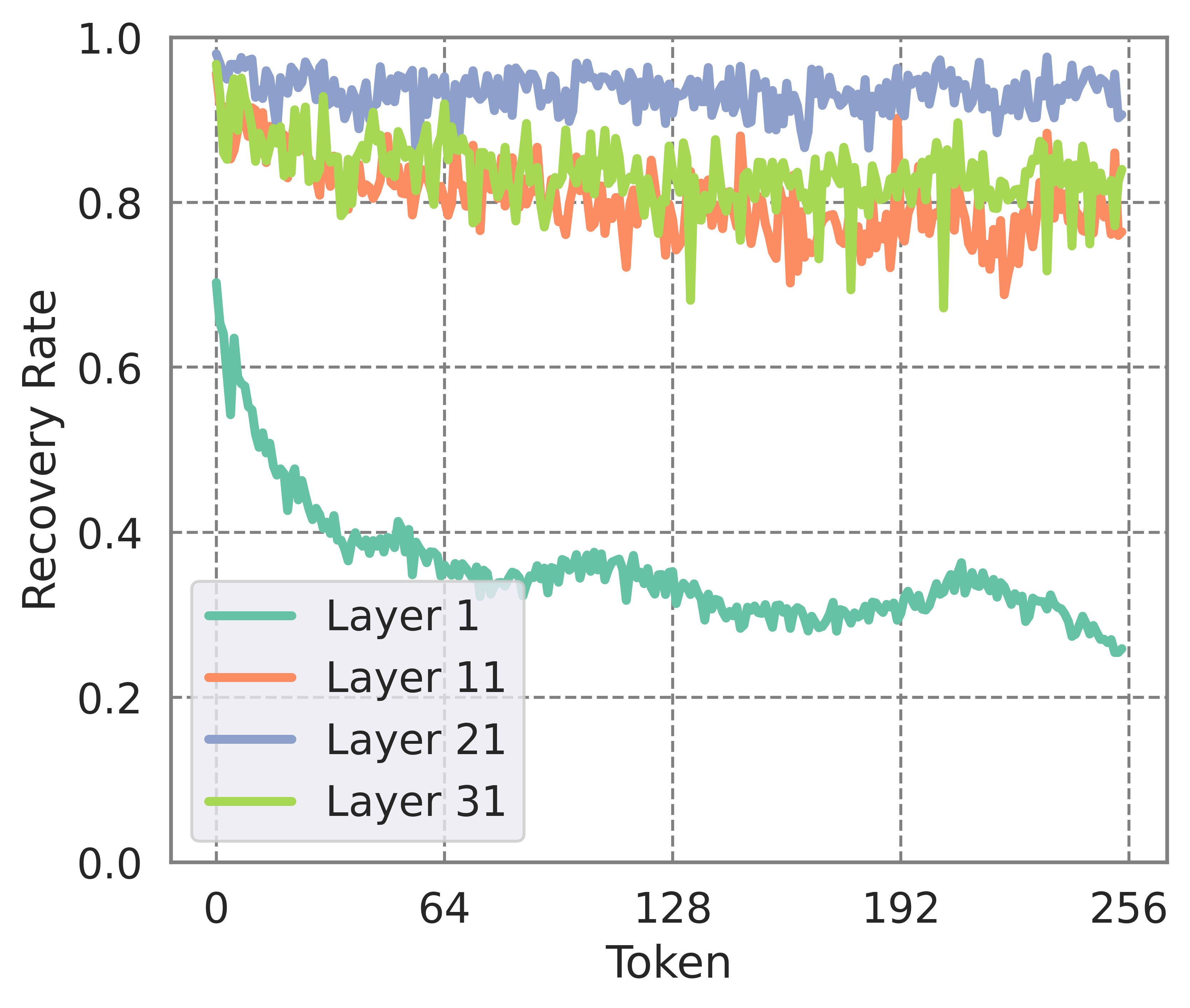
 Conclusion and Future Work
Conclusion and Future Work