Why Sequoia
Benefiting from two key advantages, Sequoia significantly accelerates LLM serving with offloading. Firstly, Sequoia is more scalable with a large speculation budget. For a given draft / target model pairs, Sequoia leverages a dynamic programming algorithm to search for the optimal tree structure, which enables a much faster growth in terms of accepted tokens with a certain budget (i.e. the size of the speculation tree). Secondly, thanks to sampling without replacement algorithm, Sequoia is robust in terms of generating temperatures, compared to top-k sampling and sampling with replacement. Apart from offloading, Sequoia provides a hardware-aware solution to adjust the size and depth of speculation trees to adapt to different hardware platforms. Sequoia can also speed up LLM inference on data-center GPUs like A100 and L40, which is discussed in detail in our paper.
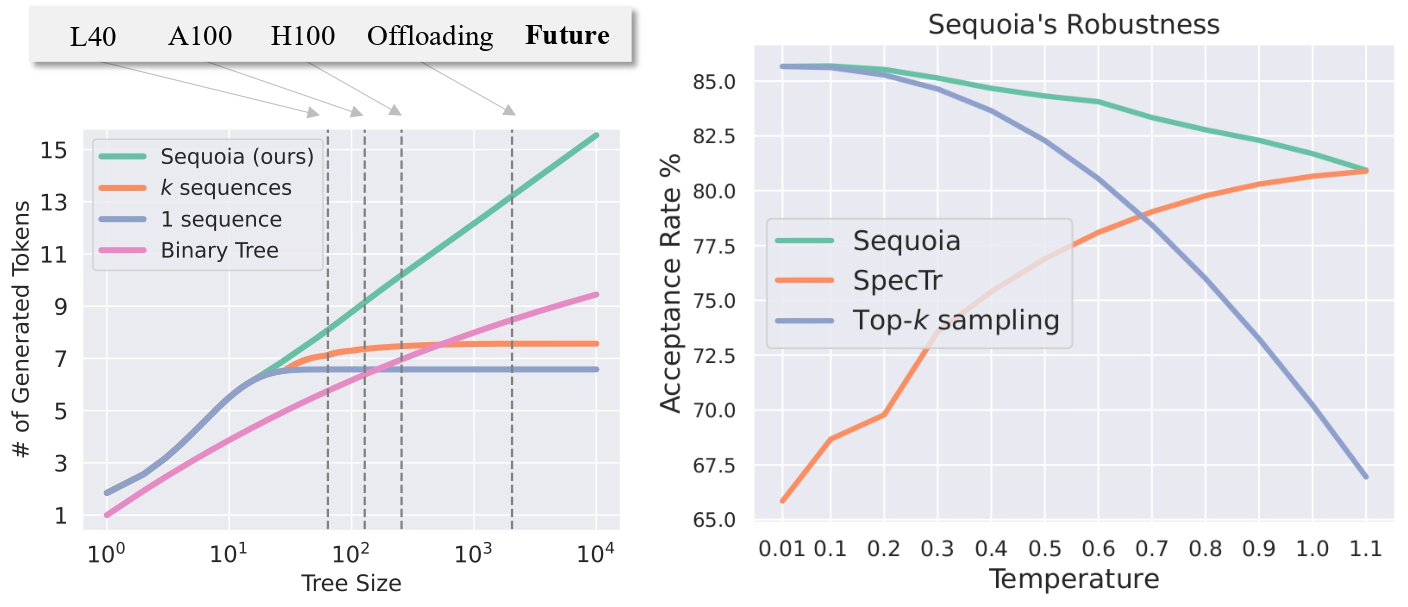
Left (Scalability): Handcrafted tree structures do not scale well with large speculation budget.
Right (Robustness): The total acceptance rate of 5 speculation tokens. Sampling with replacement (SpecTr) fails when temperature is low and Top-k sampling fails with high temperature. Sequoia, leveraging sampling without replacement, attains the highest acceptance rate.
Below we show two examples of tree structures in Sequoia. The left one has 64 nodes which is suitable for on-chip inference and the right one has 768 nodes, suitable for offloading settings.
We append more budget to nodes in previous layers with a higher probability to get accepted.

Conclusion and Future Work
Leveraging a large speculation budget, everyone can use RTX 4090 or other consumer (low-cost) GPU, e.g., AMD RX7900 with Sequoia to host very strong LLMs like 70B model without approximation, boosting the applications of AI generated content. In addition, we believe Sequoia will perform particularly well on future hardware, because it’s performance scales well with the compute/bandwidth ratio of the hardware, which has been increasing over time (e.g., V100, A100 and H100). Moreover, Sequoia, as a speculative decoding framework which mitigates the gap in the memory hierarchy, adapts to any draft/target pairs and any AI accelerators. We will stay tuned with hardware community.

BibTeX
@article{chen2024sequoia,
title={Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding},
author={Chen, Zhuoming and May, Avner and Svirschevski, Ruslan and Huang, Yuhsun and Ryabinin, Max and Jia, Zhihao and Chen, Beidi},
journal={arXiv preprint arXiv:2402.12374},
year={2024}
}